DQN: Deep Recurrent Q-Network DRQN
Can a deep RL agent function well in a partially observable world?
Let’s face it, a fully observable world is too good to be true. In reality, often we only have access to some noisy and incomplete observations. Despite this partial observability, humans can somehow still overcome the challenges and get the tasks done. However, the same doesn’t apply to the DQN agent in DeepMind’s original paper, because it is designed to operate in a fully observable world. We need a better solution to deal with partial observability.
The Challenge of Partial Observability
When an agent has access to all the information about the environment to make its optimal decision, we call it an fully observable environment. This type of environment is often formalized as Markov decision processes (MDPs). For instance, a chess game is fully observable because the player has complete knowledge about the board at any point in time. In MDPs, Markov property must hold. David Silver beautifully describes it as “the future is independent of the past given the present.” In other words, at every decision point, we have everything we need to know to make the best next move.
While MDPs are very nice to have, most real-world problems do not fall into this category. An example of partial observability could be a card game with some cards facing down that are unobservable to the player. The player can only see their own cards and the dealer’s face-up cards. Though imperfect, the player has to work with the limited information to make decisions and attempt to win the game. We call this type of environment Partially-Observable Markov Decision Processes (POMDPs).
In fact, many Atari games are partially observable when we only look at a single frame at a time. Take for instance the game of Pong, the agent needs to know both the ball’s position and velocity to decide where to move the paddle. A frame is insufficient because it only reveals the position but not the velocity.

The agent cannot rely solely rely on its knowledge of the current state to make the right decisions. In this case, the Markov property doesn’t hold anymore.
Memory can be used add information and help the agent to make better decisions. In the example of the Pong game, if a sequence of frames are available to the agent instead of just one, then it’s possible to interpret the ball’s velocity from these additional frames.
 |
 |
 |
 |
DeepMind’s approach is to stack the last four frames as the input to a DQN. With this workaround many previously POMDPs games are converted to MDPs. While it works well in simple games, there are some limitations. Mainly, DQN has a short memory, it only remembers the last four frames. For more complex games involve decision makings with memory beyond four frames, the Markov property fails to hold and the system falls back to POMDP.
Indeed, you can always add more information by stacking more frames together. But the amount to remember is proportional to the frames to store, and the controller’s memory is not without limit. With this shortcoming, it’s natural to ask whether there is a more robust solution. If there’s a network that can persist previous information while keeping its memory at a constant size, it will be very useful.
Recurrent Neural Networks
Recurrent Neural Networks (RNNs) is the neural network that does the magic. Instead of making all inputs and outputs independent as in the Vanilla Neural Network, they take in input as a sequence. RNNs are called “recurrent” because they recurrently perform the same operations to each element in the sequence. They are networks with loops to itself:
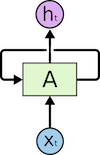
Unfold the loop, note how the output of current element in a sequence is based on the computation of the previous elements:
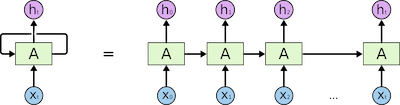
Another way to think is that the RNNs have a “memory” to make use of the previous information for current task.
RNNS are handy for tasks like watching a video or reading a piece of text. For example, when you read this blog post, your understanding of the current word is based on your understanding of the previous words. Other well known RNNs applications are: speech recognition, machine translation, image captioning, and more. If you’d like to learn about this magical network, Andrej Karpathy has an excellent post on this topic.
Deep Recurrent Q-Learning
The idea of deep recurrent Q-learning (DRQN) is to combine RNNs with DQNs to deal with the partially observable environment. Note we use Long Short Term Memory networks (LSTMs) instead of the vanilla RNNs. LSTMs are the most commonly used type of RNNs. In general, they are the same thing as RNNs, just different in the way how they compute the hidden states, and LSTMs outperform RNNs in learning long-term dependencies. I highly recommend you read Christopher Olah’s excellent post on LSTMs to understand it.
References
[1] Hausknecht, M., & Stone, P. (2015). Deep Recurrent Q-Learning for Partially Observable MDPs.